
Abstract
Predictive Monitoring in Process Mining is the discipline of predicting business processes according to the outcome or the remaining time. The relevant data source is an event log which includes all activity data regarding a process from an ERP system. Either an abstraction of the entire workflow is created for generative models, or individual traces for each entity are extracted for descriptive models.
Whereas much research has been completed in comparing quantitative results, I provide a qualitative overview of the most important literature in this field. The thesis further focuses on the technical implementation and parameters one could apply to create such procedures and prediction models. The purpose is to ensure a first level of understanding on the different realization methods of predictive process monitoring (PPM) and to understand how the authors conducted their research procedure.
As the following summary can not go into each technical detail, it will only revolve around the most comprehensive parts of my thesis. This summary will thus include an explanation about generative and descriptive models, including the pre-processing of transaction data necessary for descriptive models, as well as the integration of different information contexts. I will finally outline my findings.
Generative Models
Generative models produce a representation or abstraction of business processes that can be calculated from observations, i.e. past process transactions. These generative methods are process-aware in the predictive process monitoring context. They belong to the traditional statistics. From data, a world state is estimated that is finally taken as input in a decision theory to predict results.
Many generative models have been found in the PPM literature. Especially those approaches perform best that, firstly, put an emphasis on including activity data, which will be covered in the section about contextual information, and secondly, that can represent the control flow i.e., the process as accurately as possible. Generative models are of particular importance in research, as handling missing information is an overall problem in ERP production environments, and at the same time, a particular strength of generative approaches.
Descriptive Models
Introduction
Discriminative models focus on the boundaries of decisions. Their goal is to predict the property of the data. In contrast to generative PPM methods, they all follow a comprehensive workflow structure: first process sequences are extracted and filtered, then, they must be bucketed, then these traces are encoded, and finally a model is applied that can work with the data. This can be explained as they belong to the modern machine learning techniques. These can directly predict results based on preprocessed data, without the detour of creating a comprehensive abstraction of the real world.
Pre-Processing of Transaction Data
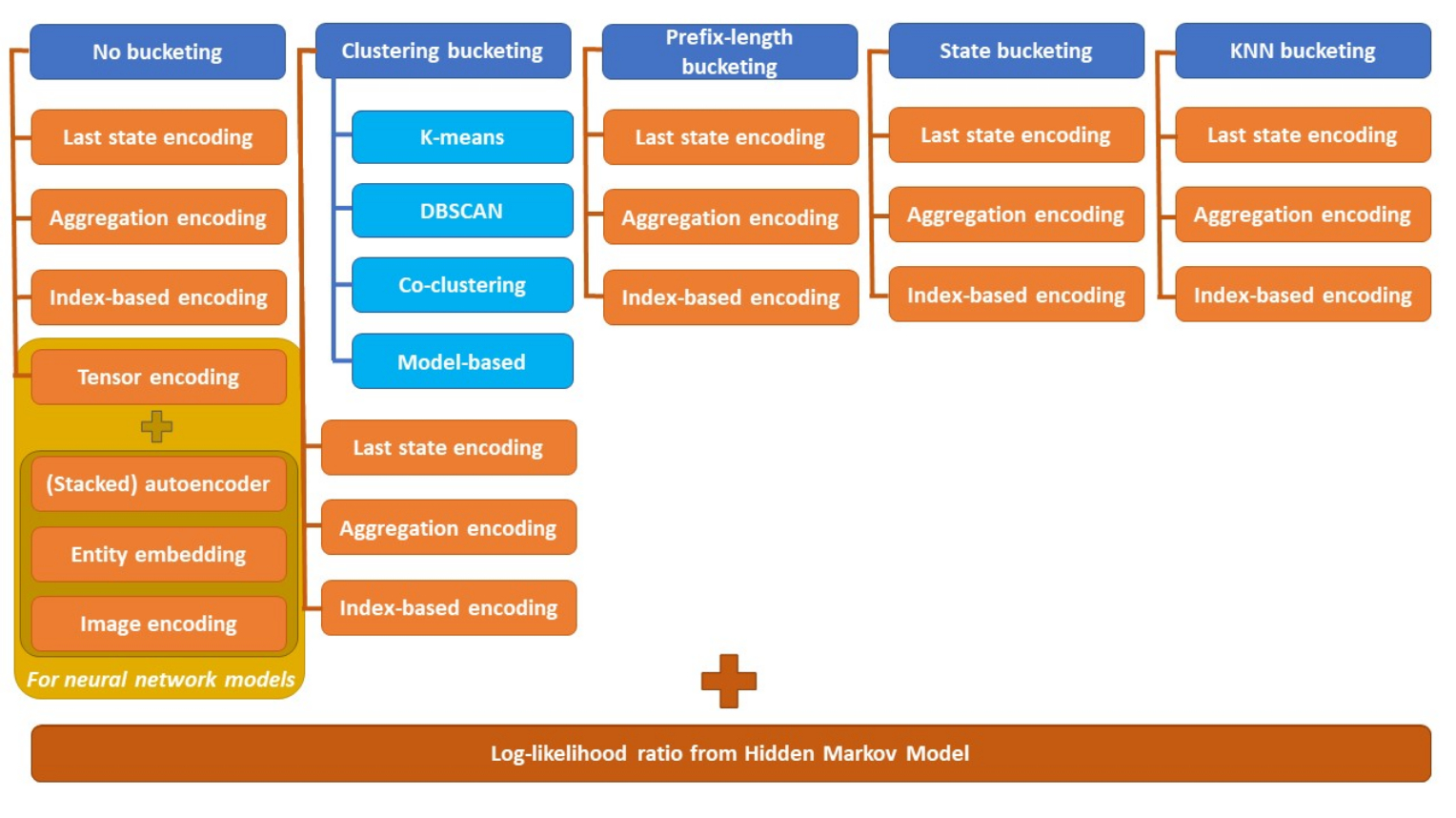
Bucketing
Trace bucketing is a procedure to divide traces with different methods. The resulting buckets serve as separate training sets for different models. Concerning the bucketing procedures, the simplest one is the so-called single bucket approach. It should be pursued if the initial training set is limited to the extent that the model could not be appropriately trained. Particularly, neural networks also do not require bucketing, as large amounts of data can be used for training. As another example, prefix length bucketing specialize a model for different points in time of process execution.
Encoding
Sequence encoding is about treating traces as complex symbolic sequences, each carrying a data payload. The sequence encoding can be situated after trace bucketing, whereas the traces need to be encoded in machine readable language i.e., in structured data. In their simplest form, they are simple symbolic sequences which do not include activity attributes. In their more sophisticated form, they describe related data in a static or dynamic manner. Last state encoding, for example, only includes the attributes of the last event of a trace, ignoring the evolution to that point.
Finding
There is no comprehensive literature review that compares all possible combinations of trace bucketing and sequence encoding according to their performance. Nevertheless, it must be said that a holistic comparison of all different combinations can be quite an extensive task. Additionally, since encoding techniques do not exclude themselves, the significance of such a paper could be limited as combinations of multiple encoding techniques would also need to be included to gain a complete overview. Lastly, there is no universal solution as different models require different processing workflows.
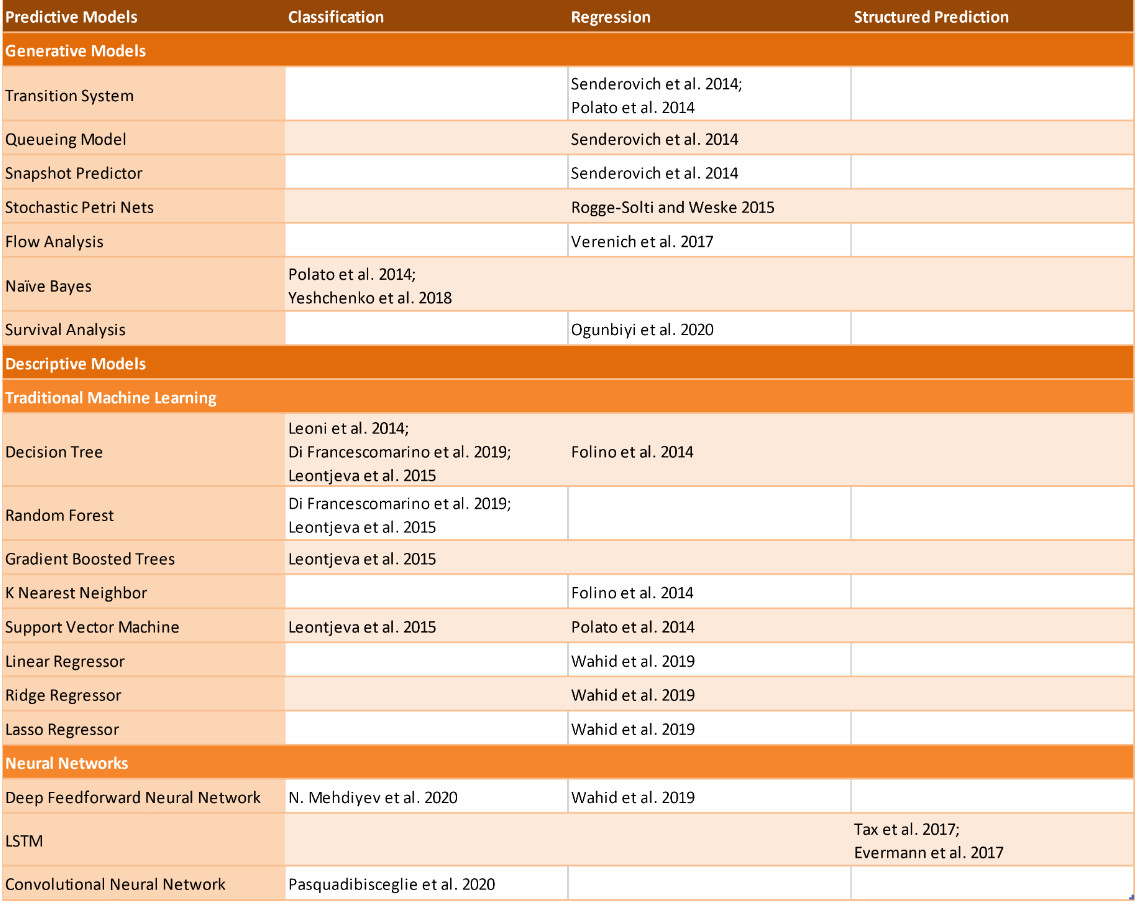
Classification, Regression and Structured Algorithms as Predictors
Overview
Classifiers categorize data into distinct labels. As categorization problems are the most fundamental, they will serve as the basic building blocks for the more complex issues. Next event and outcome predictions necessitate classifiers and both revolve around the same method.
Regressors have the commonality to predict a continuous-valued output instead of one from a finite set, in contrast to classifiers. In PPM, regressors are applied to predict the remaining time.
Structured predictors output entire sequences as predictions i.e., remaining paths of a sequence in our case. Structured predictors only include Long Short-Term Memory (LSTM) models, according to the current state of research. LSTM models belong to the Recurrent Neural Networks that are used in contexts in which the input or output range of data is not known beforehand.
Findings
Admittedly, in the implementation, there are classifiers that can serve as either classifier or regressor and vice versa. Most advanced approaches use a combination of classification and regression, as well as descriptive and generative models. For other discriminative models besides LSTM, data preprocessing requires a greater effort because they must be adjusted to work with sequence information. Furthermore, neural networks are relevant for large datasets with high dimensions. In general, discriminative models seem to be performing better than generative ones.
Integration of Contextual Information
Overview
To classify the scientific work on contextual factors as comprehensively as possible, a classification can be made based on the extent of information, whereby cause and effect get increasingly unclear the larger the scope becomes. Contextual information includes intra-case, inter-case, social, external, and spatial information to a process. At least one paper has been found for each aspect.
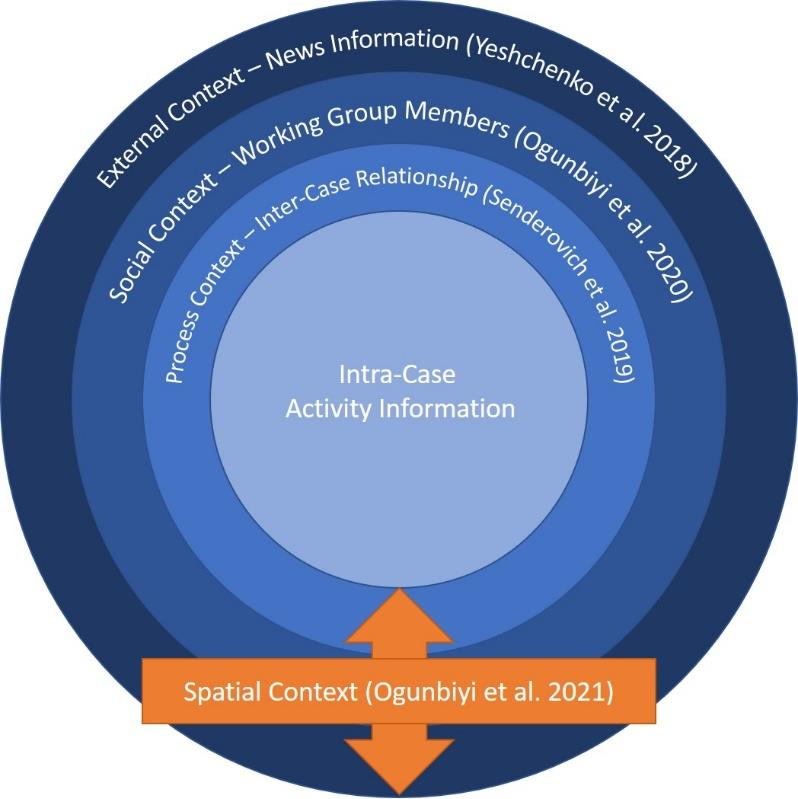
(adapted from Van der Aalst 2016, pp. 318-320)
Intra-case contextual information is information captured in an activity itself. Selected attributes to an event include the vendor, the document type, and the item category which can all be incorporated into the event log. Including intra-case information is the common approach for descriptive models.
In contrast, inter-case features, or process context information, include dependencies between different activities. The idea behind it is that predictions are also dependent on the execution of events in the same period e.g., competing for the same resource in the process context. Generative models take advantage of these features.
Regarding the social context, these factors encompass the way humans and automated agents interact within a particular organization to execute process-related activities. Friction between individuals may delay process instance, and the speed at which people work may vary.
Furthermore, external context information, as the news, can be included. Regarding this example, the information includes the fields of both the social and the external context, as the external information like the economic climate is having an impact on the people’s sentiments, such as their level of stress.
The spatial context can be seen as middle child between process, social, and external context. One successful model has been achieved by including the locations of process traces.
Findings
Beyond the intra- and inter-case contextual information, the other specialized approaches have not yet been implemented in the larger scope of PPM papers. Thus, the social, external and spatial contexts necessitate further research. Among others, external contextual information like social media, blogs etc. could be evaluated. In addition, a spatio-temporal model could be applied to further increase the remaining time accuracy.
Summary
Predictive Process Monitoring, a forecasting business operation tool, can be situated between Process Mining, as a form of comprehending the current state of a process to undertake strategic measures, and Prescriptive Process Monitoring, that interprets the prediction so that measures are described to pilot a process outcome. The review consists of both generative and discriminative models; the latter can be further broken down into prefix bucketing and encoding, implementing a machine learning model, and deciding which information context to include in the design.
All papers, that were just part of a related field of study and not necessary to implement a prediction model, were excluded. The thesis is aimed at providing a counterbalance for other quantitative reviews in this field. A large variety of findings have emerged: both generative and descriptive models play a role in current research, there is a lack of papers in the field of process suffix prediction as well as structured predictors, and the integration of a larger information context, e.g., from external sources, should be an integral part of future research.